 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGPart & RAGMask: Retrieval-Stage Defenses Against Corpus Poisoning in Retrieval-Augmented Generation
Dec 30, 2025Retrieval-Augmented Generation (RAG) has emerged as a promising paradigm to enhance large language models (LLMs) with external knowledge, reducing hallucinations and compensating for outdated information. However, recent studies have exposed a critical vulnerability in RAG pipelines corpus poisoning where adversaries inject malicious documents into the retrieval corpus to manipulate model outputs. In this work, we propose two complementary retrieval-stage defenses: RAGPart and RAGMask. Our defenses operate directly on the retriever, making them computationally lightweight and requiring no modification to the generation model. RAGPart leverages the inherent training dynamics of dense retrievers, exploiting document partitioning to mitigate the effect of poisoned points. In contrast, RAGMask identifies suspicious tokens based on significant similarity shifts under targeted token masking. Across two benchmarks, four poisoning strategies, and four state-of-the-art retrievers, our defenses consistently reduce attack success rates while preserving utility under benign conditions. We further introduce an interpretable attack to stress-test our defenses. Our findings highlight the potential and limitations of retrieval-stage defenses, providing practical insights for robust RAG deployments.
Reflective Agreement: Combining Self-Mixture of Agents with a Sequence Tagger for Robust Event Extraction
Aug 26, 2025Event Extraction (EE) involves automatically identifying and extracting structured information about events from unstructured text, including triggers, event types, and arguments. Traditional discriminative models demonstrate high precision but often exhibit limited recall, particularly for nuanced or infrequent events. Conversely, generative approaches leveraging Large Language Models (LLMs) provide higher semantic flexibility and recall but suffer from hallucinations and inconsistent predictions. To address these challenges, we propose Agreement-based Reflective Inference System (ARIS), a hybrid approach combining a Self Mixture of Agents with a discriminative sequence tagger. ARIS explicitly leverages structured model consensus, confidence-based filtering, and an LLM reflective inference module to reliably resolve ambiguities and enhance overall event prediction quality. We further investigate decomposed instruction fine-tuning for enhanced LLM event extraction understanding. Experiments demonstrate our approach outperforms existing state-of-the-art event extraction methods across three benchmark datasets.
CAMOUFLAGE: Exploiting Misinformation Detection Systems Through LLM-driven Adversarial Claim Transformation
May 03, 2025Automated evidence-based misinformation detection systems, which evaluate the veracity of short claims against evidence, lack comprehensive analysis of their adversarial vulnerabilities. Existing black-box text-based adversarial attacks are ill-suited for evidence-based misinformation detection systems, as these attacks primarily focus on token-level substitutions involving gradient or logit-based optimization strategies, which are incapable of fooling the multi-component nature of these detection systems. These systems incorporate both retrieval and claim-evidence comparison modules, which requires attacks to break the retrieval of evidence and/or the comparison module so that it draws incorrect inferences. We present CAMOUFLAGE, an iterative, LLM-driven approach that employs a two-agent system, a Prompt Optimization Agent and an Attacker Agent, to create adversarial claim rewritings that manipulate evidence retrieval and mislead claim-evidence comparison, effectively bypassing the system without altering the meaning of the claim. The Attacker Agent produces semantically equivalent rewrites that attempt to mislead detectors, while the Prompt Optimization Agent analyzes failed attack attempts and refines the prompt of the Attacker to guide subsequent rewrites. This enables larger structural and stylistic transformations of the text rather than token-level substitutions, adapting the magnitude of changes based on previous outcomes. Unlike existing approaches, CAMOUFLAGE optimizes its attack solely based on binary model decisions to guide its rewriting process, eliminating the need for classifier logits or extensive querying. We evaluate CAMOUFLAGE on four systems, including two recent academic systems and two real-world APIs, with an average attack success rate of 46.92\% while preserving textual coherence and semantic equivalence to the original claims.
Pareto GAN: Extending the Representational Power of GANs to Heavy-Tailed Distributions
Jan 22, 2021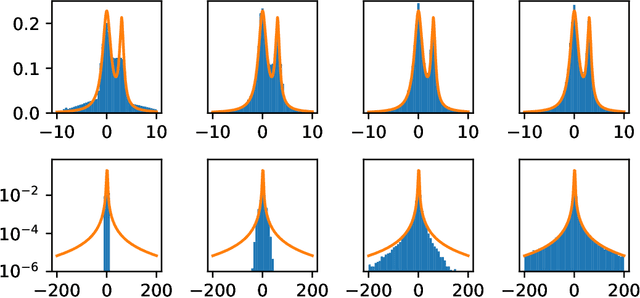
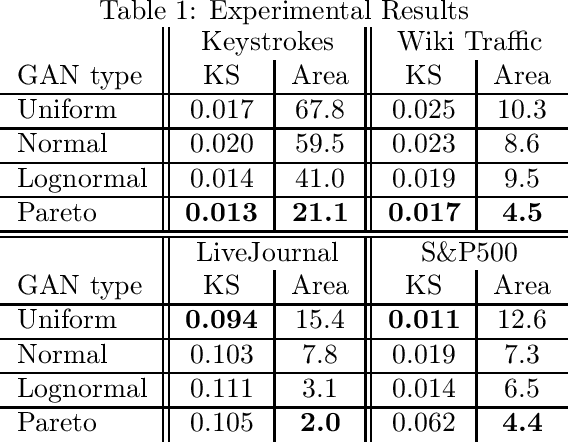
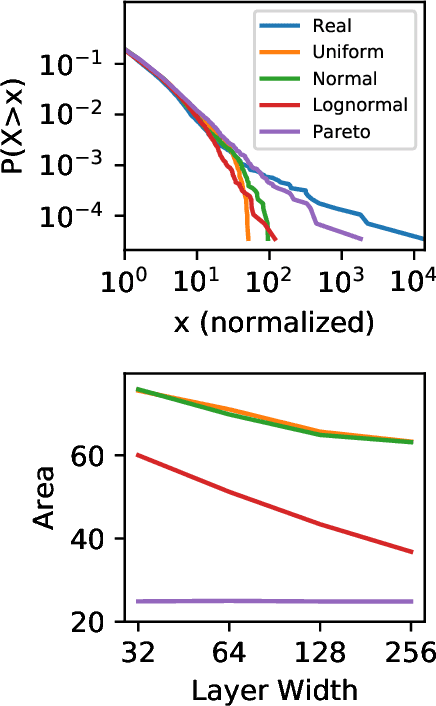
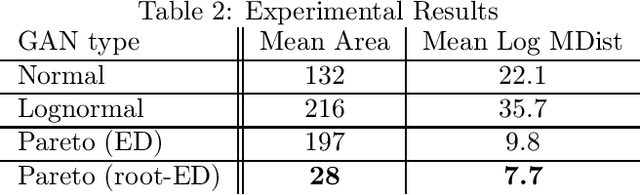
Generative adversarial networks (GANs) are often billed as "universal distribution learners", but precisely what distributions they can represent and learn is still an open question. Heavy-tailed distributions are prevalent in many different domains such as financial risk-assessment, physics, and epidemiology. We observe that existing GAN architectures do a poor job of matching the asymptotic behavior of heavy-tailed distributions, a problem that we show stems from their construction. Additionally, when faced with the infinite moments and large distances between outlier points that are characteristic of heavy-tailed distributions, common loss functions produce unstable or near-zero gradients. We address these problems with the Pareto GAN. A Pareto GAN leverages extreme value theory and the functional properties of neural networks to learn a distribution that matches the asymptotic behavior of the marginal distributions of the features. We identify issues with standard loss functions and propose the use of alternative metric spaces that enable stable and efficient learning. Finally, we evaluate our proposed approach on a variety of heavy-tailed datasets.
Limitations of the Lipschitz constant as a defense against adversarial examples
Jul 25, 2018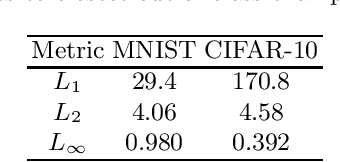
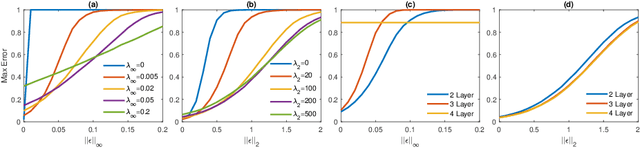
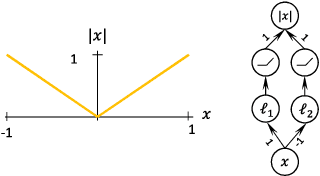
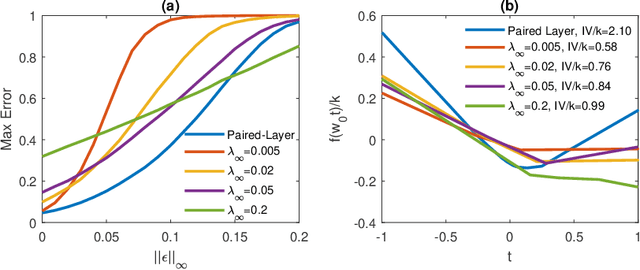
Several recent papers have discussed utilizing Lipschitz constants to limit the susceptibility of neural networks to adversarial examples. We analyze recently proposed methods for computing the Lipschitz constant. We show that the Lipschitz constant may indeed enable adversarially robust neural networks. However, the methods currently employed for computing it suffer from theoretical and practical limitations. We argue that addressing this shortcoming is a promising direction for future research into certified adversarial defenses.